 Accomodation, Entertainment and Food Services Neighborhoods in Toronto
Accomodation, Entertainment and Food Services Neighborhoods in Toronto
Abstract
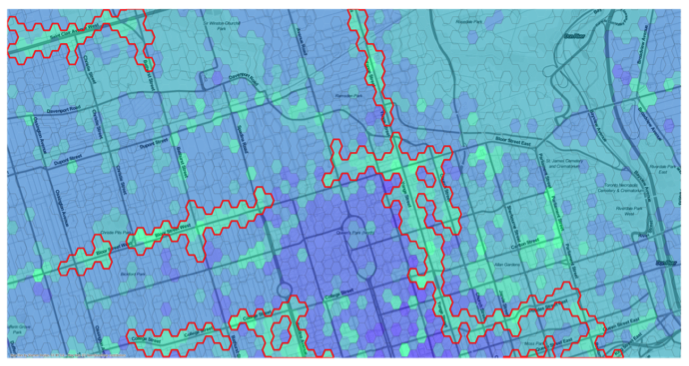
Research on neighborhoods has relied on administrative definitions that do not coincide with agents’ decision problems. This produces a spatial misalignment between administrative and “economic” boundaries that bias research findings and the policies designed around them. I propose a novel methodology to delineate neighborhoods using a machine learning algorithm that groups locations based on revealed preferences. I apply the methodology to Toronto’s industrial and residential neighborhoods and show that they are not like each other and that they remarkably differ in size and shape from their administrative counterparts. In particular, economic neighborhoods tend to have an elliptical shape and to locate around major streets. Moreover, neighborhoods are different across industries or property types. These characteristics have implications for the study the effects of neighborhood segregation and concentration.
Rolando Campusano G.
Ph.D. Candidate
Economist with research interests in the intersection of urban economics, entrepreneurship, and industrial organization.